An increasing number of systems are being built to handle the Volume, Velocity and Variety of Big Data, and hopefully help gain new insights and make better business decisions. Here, we will look at ways to deal with Big Data’s Volume and Velocity simultaneously, within a single architecture solution.
Volume + Velocity
Apache Hadoop provides both reliable storage (HDFS) and a processing system (MapReduce) for large data sets across clusters of computers. MapReduce is a batch query processor that is targeted at long-running background processes. Hadoop can handle Volume. But to handle Velocity, we need real-time processing tools that can compensate for the high-latency of batch systems, and serve the most recent data continuously, as new data arrives and older data is progressively integrated into the batch framework.
Therefore we need both batch and real-time to run in parallel, and add a real-time computational system (e.g. Apache Storm) to our batch framework. This architectural combination of batch and real-time computation is referred to as a Lambda Architecture (λ).
Generic Lambda
λ has three layers:
- The Batch Layer manages the master data and precomputes the batch views
- The Speed Layer serves recent data only and increments the real-time views
- The Serving Layer is responsible for indexing and exposing the views so that they can be queried.
The three layers are outlined in the below diagram along with a sample choice of technology stacks:
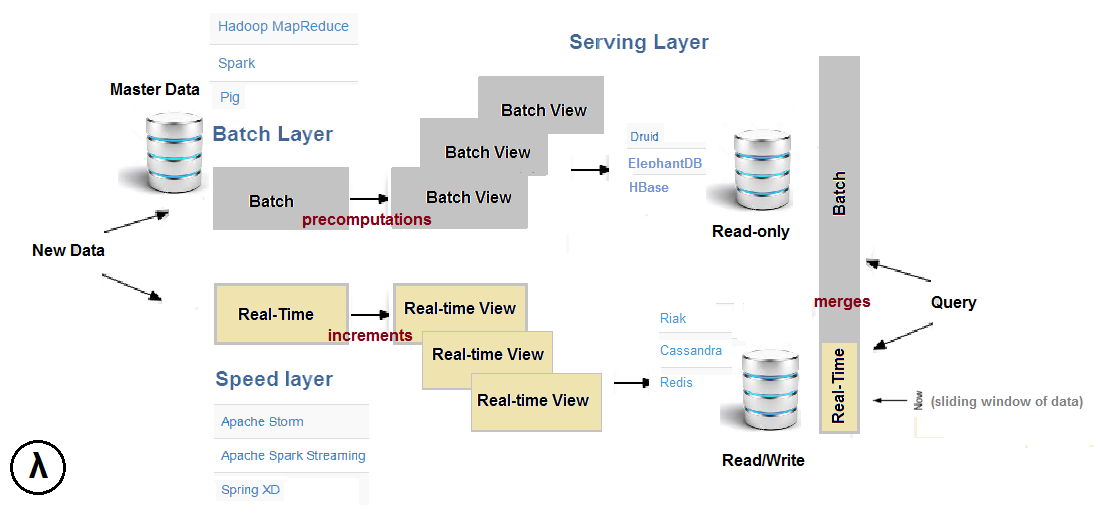
Incoming data is dispatched to both Batch and Speed layers for processing. At the other end, queries are answered by merging both batch and real-time views. Note that real-time views are transient by nature and their data is discarded (making room for newer data) once propagated through the Batch and Serving layers. Most of the complexity is pushed onto the much smaller Speed layer where the results are only temporary, a process known as “complexity isolation“. We are indeed isolating the complexity of concurrent data updates in a layer that is regularly purged and kept small in size.
λ is technology agnostic. The data pipeline is broken down into layers with clear demarcation of responsibilities, and at each layer, we can choose from a number of technologies. The Speed layer for instance could use either Apache Storm, or Apache Spark Streaming, or Spring “XD” ( eXtreme Data) etc.
How do we recover from mistakes in λ ? Basically, we recompute the views. If that takes too long, we just revert to the previous, non-corrupted versions of our data. We can do that because of data immutability in the master dataset: data is never updated, only appended to (time-based ordering). The system is therefore Human Fault-Tolerant: if we write bad data, we can just remove that data altogether and recompute.
Unified Lambda
The downside of λ is its inherent complexity. Keeping in sync two already complex distributed systems is quite an implementation and maintenance challenge. People have started to look for simpler alternatives that would bring just about the same benefits and handle the full problem set. There are basically three approaches:
- Adopt a pure streaming approach, and use a flexible framework such as Apache Samza to provide some type of batch processing. Although its distributed streaming layer is pluggable, Samza typically relies on Apache Kafka. Samza’s streams are replayable, ordered partitions. Samza can be configured for batching, i.e. consume several messages from the same stream partition in sequence.
- Take the opposite approach, and choose a flexible Batch framework that would also allow micro-batches, small enough to be close to real-time, with Apache Spark/Spark Streaming or Storm’s Trident. Spark streaming is essentially a sequence of small batch processes that can reach latency as low as one second.Trident is a high-level abstraction on top of Storm that can process streams as small batches as well as do batch aggregation.
- Use a technology stack already combining batch and real-time, such as Spring “XD”, Summingbird or Lambdoop. Summingbird (“Streaming MapReduce”) is a hybrid system where both batch/real-time workflows can be run at the same time and the results merged automatically.The Speed layer runs on Storm and the Batch layer on Hadoop, Lambdoop (Lambda-Hadoop, with HBase, Storm and Redis) also combines batch/real-time by offering a single API for both processing paradigms:
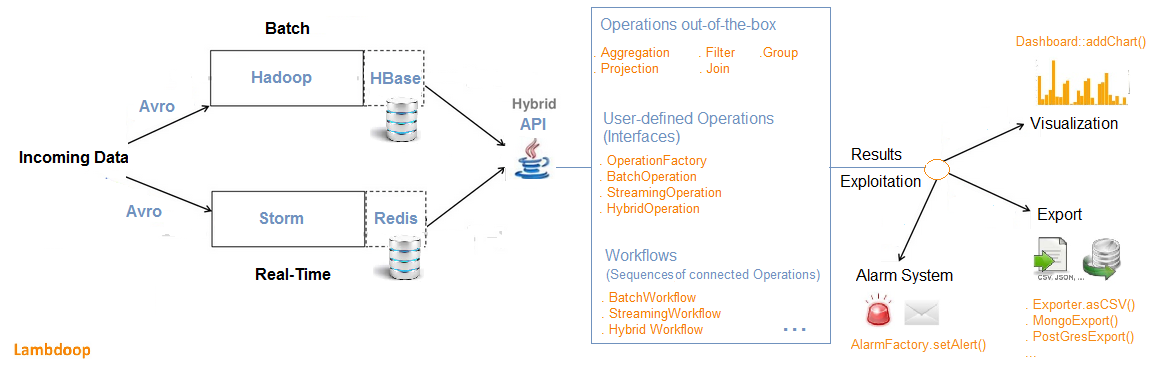

The integrated approach (unified λ) seeks to handle Big Data’s Volume and Velocity by featuring a hybrid computation model, where both batch and real-time data processing are combined transparently. And with a unified framework, there would be only one system to learn, and one system to maintain.
No comments:
Post a Comment